 Вход
Вход Регистрация
Регистрация






Мы всё таки пришли к выводу как нужно всё таки заниматься, или до сих пор спорим?
Мы - да.


 74 голосов
74 голосов

Завсегдатай


Наблюдаю за темой, ну ооочень давно. Мы всё таки пришли к выводу как нужно всё таки заниматься, или до сих пор спорим?
body_by_mma

Никогда не нужно забывать, что самые высокие темпы гипертрофии получил коллега из Норвегии - профессор Рефснес. При использовании 4-20 КПШ на мышцу за тренировку. Исследование 126!
Интересно было бы, если бы они сравнили свою срань и свои выводы относительно важности для гипертрофии объёма выполняемой работы с работой Рефснеса.
Думаю, выводы мгновенно бы поменялись. 
Сообщение изменено: Михалы4 (31 августа 2018 - 11:55)
Новичок

I want to address the comments and analyses being made on this paper.
First, I take my integrity as a researcher and statistician very seriously. So when I see comments like "We found what we wanted to find" or that we were playing statistical games or deliberately distorting the data, especially from people with little knowledge on statistics, it bothers me.
The idea that we're "finding what we want to find" is ludicrous. When Brad first invited me to be the statistician on this study, I was hoping there would be a volume ceiling effect. I WANTED to see no difference between groups. Hell, I train myself...I would have loved to see equivalent or even superior gains in the lowest volume group. Why the hell would I want to see a weekly volume of 45 sets on quads as superior?
The idea that we're playing statistical games is also false. If I wanted to use statistics to make it look like the high volume group was superior, I would've used simple t-tests without multiple comparison adjustments or some other method that would bias the analysis. Rather, I chose BEFORE I EVEN SAW THE DATA on mixed model repeated measures and on baseline-adjusted ANCOVA on change scores, because those were the most appropriate for the data I would be getting (the mixed model analysis ended up being redundant with the ANCOVA and one of the reviewers asked us to remove the results for that...the findings were exactly the same). I also decided to use both frequentist and Bayesian because Bayesian allows for more probabilistic assessments of the data rather than just simple significance threshold testing. If anyone was familiar with our previous papers, you'll see that the analyses chosen are the same or similar to ones we've done on other papers, so it's not like we're doing something new.
Second, I want to address Lyle's claims that the high volume group simply had "catch-up" growth. Lyle is basing this off of the fact that the raw means for muscle thickness were non-significantly lower in the 5-set group, and muscle thickness measures ended up being somewhat similar by the end of the study.
The problem with Lyle's analysis is that he's simply looking at the mean and not the individual data. This is why we did the baseline-adjusted ANCOVA. It adjusts for any differences in baseline values; it essentially levels the playing field between the groups. And we still saw the difference even after adjusting for the differences in baseline.
Сообщение изменено: Dlor (31 августа 2018 - 04:27)
Аксакал

дядя Толя, срочно через гугл и утри нос там! Русские качки не только лаптем протэин хлебают!
Чтобы еще русский рупор Лайла с Лайлом поссорился?
Я думал, надо Рихаду предложить, как профессиональному переводчику. Все равно они уже с Лайлом поссорились (или с Боржем?)
Новичок

Интересно было бы, если бы они сравнили свою срань и свои выводы относительно важности для гипертрофии объёма выполняемой работы с работой Рефснеса.
Думаю, выводы мгновенно бы поменялись.
Так Вы сторонник идеи что eccentric contractions лучше для гипертрофии чем обычные тренировки?
crusader of philosophy

И с тем и другим , вроде. Борже он андрогелем достал, а Лайлу указал на его несовершество английского))). Так у Лайла своих тараканов хватает, то еще и пиздюковских он терпеть на смог и посоветовал найти себе хобби.Чтобы еще русский рупор Лайла с Лайлом поссорился?
Я думал, надо Рихаду предложить, как профессиональному переводчику. Все равно они уже с Лайлом поссорились (или с Боржем?)
Аксакал

Димыч я

... DumbI4: the highest volume condition for the quads amounted to 45 sets per week, which resulted in markedly greater hypertrophy than the other two conditions (9 sets and 30 sets). Не первый раз такой разброс!
Михалыч не любит, когда много умного и на англицком
апд: но дяде Толе, как видно выше, абсолютно параллельно
Сообщение изменено: DumbI4 (31 августа 2018 - 06:46)
Новичок
Итого, больше всех зашкварился Лайл, Шоенфельд (возможно) чуть-чуть из-за формирования маленьких групп, а Кригер молодец.
Согласен - на таких маленьких выборках выявить выбросы - очень сложно (практически невозможно) - поэтому как-то серьезно относится к результатам таких исследований не приходится.
Мужской подход

Сравнение средних значений на глаз - это дилетантство. Как минимум, здесь не учитывается характер распределения сравниваемого признака, то есть то, насколько значения в выборке сгруппированы вокруг среднего. Проще говоря, дисперсия признака. А также упускается характер распределения - при асимметричных распределениях среднее значение вообще становится бесполезным. Поэтому нужно использовать методы анализа, которые бы учитывали не только средние значения, но и характер распределения сравниваемого признка в группах, а также были чувствительны к дополнительным факторам, способным повлять на результат.
Помимо этого, мы прекрасно понимаем, что очень сложно в такой эксперимент (квазиэксперимент, точнее) набрать испытуемых с одинаковой выраженностью сравниваемого признака на старте.
В идеале для такого эксперимента нужно было бы набрать однояйцевых близнецов-тройняшек, а затем тренировать кормить их одинаково, чтобы стаж и результаты в силовухе и мышечном развии совпадали. И только потом запускать эксперимент с разным количеством подходов в упражнениях.
Мужской подход
Далее, для тех, кто думает, что среднестатистическое ничего не значит. Вот сгенерированные компьютером среднестатистические женские лица разных рас. Вобрали в себя все значения и получилось все равно лицо!

Аксакал
Вы что, все статистикомены курсы какие-то проходите по выражению мыслей так, чтобы никто включая вас ничего не понял?! Я мозг окончательно сломал.
Знаете что характеризует дурь статистики в целом? 90 человек ели капусту, 10 ели мясо, по статистике 100 ели голубцы. Но не этот эксперимент.
Ну вот, раз в ход пошел быдлинг от
КригераРихада значит он признал, что не прав.
чем больше мяса/силы уже есть, тем медленнее оно растет
Ничего, что ты сравниваешь РАЗНЫХ людей? Полно начинающих, у которых больше мяса/силы, чем у тебя и которые быстрее тебя растут (да, да, знаем - они генетики, белые солдатики, быдлобелковики и рыготники, но тем не менее ты снова сказал глупость).
Сообщение изменено: aid (31 августа 2018 - 10:41)
Новичок
Знаете что характеризует дурь статистики в целом? 90 человек ели капусту, 10 ели мясо, по статистике 100 ели голубцы.
Такое утверждение скорее характеризует дурь того, кто пытается оперировать статистическими понятиями, не имея о них достаточных представлений.
Среднее значение, оно же математическое ожидание, справедливо лишь при оценке континуальных числовых рядов, представляющий собой результаты измерений (измерений, это если мы про эксперименты говорим). Да и то, будет информативно при распределении этих чисел, близком к нормальному. Вот такому (горизонтальная ось - зафиксированное значение, вертикальная - частота встречаемости значения в выборке):
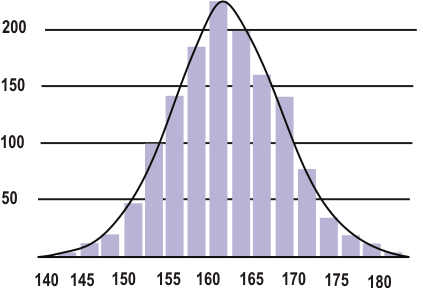
При таком распределении среднее значение максимально часто встречается в группе. И чем ближе значение к среднему, тем, соответственно, чаще оно будет встречаться. Поэтому так все над средними значениями и трясутся - они более-менее позволяют оценить распределение измеряемого признака в группе. Но забывая при этом, что среднее значение ничего не несет, если не учитывается характер распределения значений. Для распределения, не соответствующего нормальному, среднее значение нужной информации не несет (понять, какое значение встречается в группе максимально часто). Но это ничего, есть еще медиана для таких случаев.
Плюс к этому, информативности добавит еще и стандартное отклонение, так как позволит оценить, как сильно сгруппированы значения относительно среднего. Чем стандартное отклонение меньше, тем сильнее значение в группе сгруппированы вблизи среднего.
Поэтому в статьях указывают всегда среднее значение (M) и стандартное отклонение (SD). Очевидно же, что не у всех в группе будет встречаться среднее значение, у кого-то будет меньше, у кого-то больше. Но если признак распределен в группе нормально, то среднее будет встречаться максимально часто. Чем сильнее распределение отклоняется от нормального, тем менее информативным будет становиться среднее значение.
На выборке из 10 наблюдений оценить нормальность распределения признака - задача достаточно глупая. Тем не менее, наличие более-менее нормального распределения признака в группах - необходимое условие применения многомерных методов типа ковариационного анализа. Хотя эту проблему легко решить увеличением количества испытуемых, так часто не делают. Финансовые органичения и т.п. Хотя вычислить необходимый объем выборки для достоверных результатов не так уж и сложно. Но если организовать хороший воспроизводимый эксперимент, то потом на новые денег не дадут. Зачем, если все уже доказано и только будет подверждаться. Поэтому мы лучше будем проводить маленькие кулуарные, каждый раз получая противоречивые данные и заявлять об очередной революции в науке ))
Это проблема не только обсуждаемого эксперимента, но и всей науки в целом.
90 человек ели капусту, 10 ели мясо, по статистике 100 ели голубцы
Это по какой-то воображаемой статистике. Она так не работает. Для таких данных вообще не применимо среднее значение.
Рекомендую начать знакомство с книжки В. Савельева "Статистика и котики". Там хорошо про типы шкал и меры центральной тенденции написано. С картинками.
Далее, для тех, кто думает, что среднестатистическое ничего не значит. Вот сгенерированные компьютером среднестатистические женские лица разных рас. Вобрали в себя все значения и получилось все равно лицо!
Давай так. Покажи мне на картинке, где тут среднестатистическое? И среднестатистическое чего? Напоминаю, что для него нужно суммировать значения всех чисел и поделить на количество чисел. Так и где тут измерения в числовой форме и количество чисел? Что тут складывали и делили? Это усредненное лицо, а не среднестатистическое. Не надо путать. Если бы оно было репрезентативным "среднестатистическим", то оно встречалось бы максимально часто. К тому же, твой пример - это не пример выборочного экспериментального исследования с контролируемыми факторами.
Чтобы комментировать исследования, надо хотя бы иметь базовые представления об их проведении и анализе данных. Без последнего при комментариях можно просто пернуть в лужу. Что, например, Лайл и сделал. И не только он. Лучше тогда не комментировать, а пропускать в статье пункты про выборку, методы и результаты, сразу переходя к обсуждению результатов и выводам. И верить экспертам. Либо книжки про статистику почитать. Но они скучные.
Сообщение изменено: Dlor (01 сентября 2018 - 12:05)
Мужской подход
Давай так.
Фуф. Статистикоманы в погоне за математическими оправданиями не видят чисел.
Вы можете мне по человечески (не как статистик Кригер или Длор, в стиле "кручу верчу запутать хочу") ответить на три простых вопроса:
На всякий случай графики здесь: https://bodyrecompos...ch-review.html/
Сообщение изменено: rihad (01 сентября 2018 - 08:09)
Аксакал
Поэтому мы лучше будем проводить маленькие кулуарные, каждый раз получая противоречивые данные и заявлять об очередной революции в науке ))
Ну тут вы уже грешите на Шонфилда. Так обычно только альты делают.
body_by_mma
В идеале для такого эксперимента нужно было бы набрать однояйцевых близнецов-тройняшек, а затем тренировать кормить их одинаково, чтобы стаж и результаты в силовухе и мышечном развии совпадали. И только потом запускать эксперимент с разным количеством подходов в упражнениях. Но хрен такое реализуешь.
Таких близнецов полно - правый бицепс и левый бицепс.
На каждом индивидууме можно найти как минимум 10 пар близнецов для сравнения.
Чем не эксперимент?
Уж проверить такую примитивную вещь как количество рабочих подходов и реакцию на них - запросто. Вот только мозгов у этих "учёных" на такое не хватит. Ибо там все... идиоты.
Мусор на входе - мусор на выходе.
Наиболее точное описание данного "эксперимента".
( ͡° ͜ʖ ͡°)ᅠ

Если 90 человек ели капусту а 10 мясо то нормальная статистика именно это и покажет.Знаете что характеризует дурь статистики в целом? 90 человек ели капусту, 10 ели мясо, по статистике 100 ели голубцы.
body_by_mma
A potential difference in findings is that their study included single-joint training for the biceps whereas ours just performed multijoint pulling movements (i.e. rows and lat pulldowns).
Аххххахаха....
Это ж какими идиотами надо быть, чтобы ставить НАУЧНЫЙ эксперимент по развитию бицепса - и при этом использовать подтягивания в качестве развивающего упражнения!..
-------------
А потом прочитал рассуждения Длора о желаемой величине выборки - и понял в чём тут дело, всё встало на свои места. В погоне за "клиентурой" (испытуемыми), "учёные" обратили своё внимание на места лишения/ограничения свободы: армию/интернаты/военные училища и прочее. А там, конечно же, ни о какой штанге и подъёмах на бицепс речи быть не может. Поэтому все по свистку просто загоняются на турник, и.... Эксперимент начат!
----------
И это... ЭЛИТА мировой науки...
Ну, как они про себя думают.
----------
Я одному такому педику высказал пару мыслей (вполне корректно и аргументированно) по поводу его "научных" высказываний, так она, не выдержав малейшей критики, вознегодовала и меня забанила, а все посты из переписки удалила.
Сообщение изменено: Михалы4 (01 сентября 2018 - 11:15)
Мужской подход
Если 90 человек ели капусту а 10 мясо то нормальная статистика именно это и покажет.
Вот прям 90% едят капусту а 10мясо и 0% -голубцы
Невозможно или очень затруднено проследить и козацию, и корреляцию. Кто покупал капусту? когда покупал мясо? кто ел голубцы? Поэтому тот кто смотрит на все глазами статистико-мана видит реальность искаженной, а 5-сетовой народ-то де неплохо живет, раз голубцы ест. А в этом исследовании усредненная тенденция была наглядно продемонстрирована. Для чего еще было фигачить эти графики со средним+девиацией если в результате все равно вывод оказался другим? Они увидели только большую прибавку у 5-сетовиков, что и Лайл видел и я вижу, но закрыли глаза на (а) более низкие замеры 5-ти сетовиков до исследования, и (б) одинаковые показатели обеих групп после исследования. Нельзя исключить, что если 5-сетовая группа тоже бы занималась по 3-сетовке, она бы все равно была одинакова с нынешней 3-сетовой группой из-за чуть более новичкового эффекта и исключения возможного перетрена (напомню, что здесь было не просто 45-сетов в неделю, а их заставляли быдловать чуть ли не каждый сет до отказа, снижая вес от сета к сету)..
Сообщение изменено: rihad (01 сентября 2018 - 11:34)
0 пользователей, 7 гостей, 0 скрытых
 Наверх
Наверх











